Виртуализация позавчера: виртуальная память и стандартные интерфейсы операционных систем
Вообще, «виртуализация» - это один из краеугольных камней современной вычислительной техники. По правде сказать, «виртуален» и «невещественен» любой компьютер, начиная еще с первых «пентиумов»: ведь, по сути, любая выполняющаяся на них команда, инструкция, операция в той или иной степени виртуальна. Программы работают с виртуальной, а не физической оперативной памятью, процессоры «на лету» перекодируют x86-инструкции в свой внутренний RISC-подобный формат, драйвера устройств и операционные системы прячут под стандартными интерфейсами доступное в системе оборудование. Это зачастую медленно, это почти всегда сложно, но это - единственный способ хоть как-то гарантировать относительную надежность и сравнительную эффективность той чудовищно, непомерно огромной системы, которую мы называем современным компьютером.
Но что же тогда скрывается за модными в последние полгода словами «технологии виртуализации», которые, как уверяют нас гранды процессоростроения, станет не менее весомым аргументом в вопросе покупке нового процессора, чем еще года два назад была возросшая производительность?
У большинства русскоговорящих читателей слово «виртуальный», вопреки его изначальному происхождению, наверное, вызывает примерно одинаковые ассоциации с чем-то невещественным, несуществующим на самом деле. Но изначальный смысл его в вычислительной технике гораздо конкретнее и проще - «виртуальные» объекты здесь всегда означают некие абстрактные интерфейсы, за которыми скрывается реальное оборудование. Основная идея, хорошо прослеживающаяся здесь последние лет двадцать - это стремление максимально упростить задачу разработчикам программного обеспечения, предоставив каждой программе (в идеале) по стандартному «виртуальному компьютеру», на котором она сможет работать без учёта вообще каких бы то ни было сторонних факторов - компьютера, на котором она запущена, или других работающих на этом же компьютере программ.
И, надо сказать, результаты здесь были достигнуты впечатляющие. Первые процессоры работали непосредственно с «физической» оперативной памятью, напрямую указывая в программе конкретную ячейку в модуле памяти, с которой они работали. Получалось что-то вроде «модуль памяти #1, микросхема 4, банк 3, строка данных 63, байт 13, - или, в двоичной нотации, «модуль 01, микросхема 01000, банк 11, строка данных 0111111, байт 01101». Эти числа записывались подряд - и получался адрес 010100011011111101101, то есть 669677 в привычной нам десятичной нотации. При соблюдении минимальных ограничений на организацию модулей памяти при таком способе записи фактически получается, что мы нумеруем ячейки памяти идущими подряд числами, начиная с нуля и заканчивая некоторым большим числом. А это удобно и проектировщикам «железа», и программистам. (Кстати, именно отсюда пошло правило «объем модуля памяти должен являться степенью двойки» - при таком подходе все младшие биты физического адреса модуля получаются допустимыми, и в нумерации адресов физической оперативной памяти не возникает «дырок»). Вот с этими «физическими адресами памяти», образующими отрезок на числовой прямой, первые программы и работали. Система была по своему достаточно изящная, но, к сожалению, совершенно не приспособленная для одновременного исполнения нескольких программ, - в лучшем случае одна программа в компьютере могла на время передавать управление другой.
Вообще, о приёмах работы того времени можно составить неплохое впечатление, если вспомнить, что модули привычной нам динамической оперативной памяти (DRAM), требующие регулярной «подзарядки», программисту в те дни приходилось «обновлять» («регенерировать») самостоятельно. Дело в том, что модули DRAM сравнительно быстро теряют хранящуюся в них в виде заряда микроконденсаторов информацию («быстро» здесь означает «за миллисекунды»), и в то время эту особенность данного типа памяти приходилось учитывать «вручную», то есть программными средствами прописывая обращения к ячейкам («столбцам») и тем самым регулярно обновляя хранящуюся в памяти информацию.
Лишь позднее функцию регенерации памяти возложили на схемотехнику и микросхемы системной логики (контроллеры памяти) «научились» проводить регенерацию памяти автоматически, в фоновом режиме и незаметно для программиста. Какая уж тогда многозадачность - за регенерацией бы уследить...
Впрочем, сложность, связанная с необходимостью учёта наличия в физической оперативной памяти одновременно нескольких программ (и совершенно разной информации - кода, данных, стека, управляющих структур) - это только полбеды. Главная же беда заключается в том, что в любых программах встречаются различные ошибки (причем, чем сложнее программа, тем этих ошибок больше), очень часто приводящие в первую очередь как раз к порче оперативной памяти по случайному адресу. И «заглючившая» программа, работающая с физической оперативной памятью, в большинстве случаев будет попросту «убивать» не только саму себя (а иногда - и не столько), сколько окружающих её «соседей» по памяти.
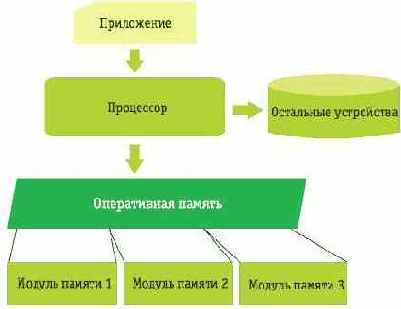
Схема 1. Компьютер без виртуализации
Как же разделить и защитить работающие в физической оперативной памяти программы друг от друга? Простейшее решение, которое приходит в голову, - просто «нарезать» эту память («большой отрезок» адресов) небольшими кусочками (меньшими отрезками адресов - сегментами). Каждый такой кусочек задаётся координатами его «начала» (первым адресом отрезка) и «длиной» (количеством адресов). Любой адрес этого отрезка считается как расстояние между этим адресом и первым адресом отрезка («смещение» от начала сегмента). Вместо того чтобы работать с физическими адресами, программы работают с этими смещениями и сегментами, - реализовать это совсем не так уж трудно, причём, выделив каждой программе даже не по одному, а по нескольку сегментов - сегмент для машинного кода программы, сегмент для её данных, сегмент для организации стека, и т.д.
Подобная система называется сегментированной моделью оперативной памяти, в архитектуре x86 она появилась в процессорах i80286 (где получила название «защищенного режима») и исчезла из этой архитектуры только с переходом к 64-битным наборам инструкций AMD64/Intel EM64T.
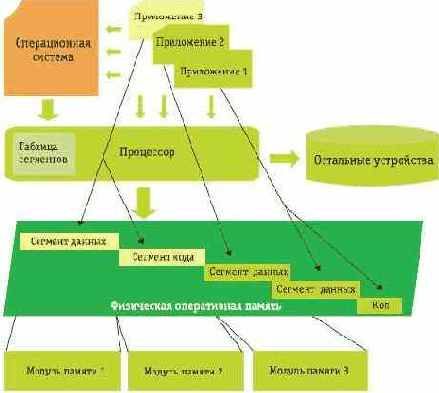
Схема 2. Сегментированная память
Что мы получаем от перехода к сегментации? Во-первых, защиту одних программ от других: процессор проверяет каждое обращение программ к памяти и контролирует, чтобы они не вышли за пределы выделенных им сегментов. Во-вторых, - и, пожалуй, это даже гораздо важнее - радикальное повышение удобства программирования. Нам не нужно задумываться над тем, что на нашем компьютере вообще существуют другие программы - каждой из них обеспечено «виртуальное» пространство, в котором присутствует даже не одна, а целых три независимых друг от друга «памяти», выделенные ей и только ей, где хранятся ключевые структурные части любой запущенной программы - код, данные и стек. Нам не нужно подстраиваться под особенности конкретной версии операционной системы (а это ведь тоже как минимум еще одна программа, запущенная на компьютере!), мы можем использовать для всех случаев жизни совершенно одинаковый программный код.
Эффективная схема? Вполне! Она работает, она удобна, доступна и понятна, так что многие любители ассемблера до сих пор с удовольствием ею пользуются. Но долго она не продержалась, поскольку, как легко догадаться, особенной гибкостью в использовании не отличается. Как мы изначально «нарежем» память ломтиками, - так оно в будущем и останется: выделим слишком много - какие-то области останутся неиспользованными и простаивающими; выделим слишком мало - не сможем в нужный момент увеличить этот объём. Помнят ли еще программисты старые добрые DOS-овские среды разработки от Borland, где в опциях компилятора указывалась «модель памяти», в которой определялся размер и количество используемых в программе сегментов? И помнят ли пользователи замечательную утилитку mem и знаменитое Not enough memory, которыми так радовали глаз пользователя ранние «персоналки»?
Одним словом, даже в те времена существовали лучшие решения, и в следующем, первом по-настоящему современном поколении x86-х процессоров (80386) вслед за процессорами Motorola и мэйнфреймами появилась основа любых современных многозадачных ОС - виртуальная память.
Об удачности этой разработки говорит хотя бы то, что вплоть до перехода к 64-битным наборам инструкций «ядро» любых x86 в точности соответствовало стандарту IA-32 (Intel Architecture for 32-bit), введённому Intel для i386 (так что, в принципе, на «трёшках» должны работать любые 32-битные программы, не задействующие слишком современных функций).
Виртуальная память() - это логическое развитие идеи сегментированной памяти, когда мы переходим от вполне конкретным образом преобразуемых в физические «линейных» адресов защищенного режима x86 к совершенно абстрактным «виртуальным» адресам. Ведь, по большому счёту, для работающей на компьютере программы совершенно безразлично, что за «физические» ячейки памяти она использует! Ей нужен просто некоторый диапазон адресов, по которым она сможет сохранять свои данные, а что за этими «цифирками» на самом деле скрывается, ей глубоко безразлично. Главное - чтобы процессор знал, как эти абстрактные цифры (виртуальные адреса) переводить во вполне конкретные инструкции для контроллера памяти (физические адреса).
Как это делается на практике? Вся доступная процессору физическая оперативная память разбивается на небольшие кусочки размером 4 Кбайт или 4 Мбайт - «страницы». При этом используется та же схема, что и при разбивке физических адресов на адреса конкретной ячейки памяти: младшие 12 или 22 бит виртуального адреса обозначают смещение данного адреса от начала страницы, а старшие биты (от 10 до 50) - номер страницы. Когда процессору требуется вычислить физический адрес по виртуальному, он просто разделяет виртуальный адрес на номер страницы и смещение, заглядывает в таблицу, где для каждого номера указаны координаты начала страницы в физической памяти, и прибавляет к полученной координате смещение(). Упомянутая табличка страниц называется таблицей трансляции адресов виртуальной памяти (или просто таблицей трансляции), и размещается она в виде B-дерева в самой обыкновенной оперативной памяти, что позволяет создавать без большой избыточности сколь угодно большие быстродействующие таблицы трансляции.
Работает это дерево, правда (как и всё, связанное с оперативной памятью), по-прежнему не очень быстро, и поэтому процессор кэширует ранее определенные соответствия «номер страницы - запись в таблице трансляции» в специальном кэше - буфере трансляции виртуальных адресов (Translation Look-aside Buffer, TLB).
Детали таблицы трансляции
Фраза про B-дерево может прозвучать устрашающе, но на самом деле скрывается за этим не такая уж и сложная технология. Двоичный номер виртуальной памяти, по всё той же доброй традиции, «разрезается» на несколько кусочков небольшого размера (по 10 бит): к примеру, 00000000001111111111010101010101 - превращается в 0000000000 + 1111111111 + 010101010101. Первая часть адреса - 0 - это «номер директории», вторая - 1023 - «номер страницы», третья - 1365 - смещение от начала страницы.
Что дальше с этим всем делается? В процессоре есть специальный регистр под названием CR3 (Control Register #3), в котором записывается «указатель на таблицу трансляции» - физический адрес, по которому в памяти располагается «таблица директорий». Эта самая таблица - это 1024 записи длиной по 32 (или 64) бита, в которых записаны физические адреса «таблиц страниц», соответствующих той или иной директории. У нас директория номер ноль, а потому процессор, декодирующий виртуальный адрес, вычисляет сумму регистра CR3 с нулём и получает адрес нужной ему «таблицы страниц». Вот в этой таблице (тоже из 1024 записей длиной 32 или 64 бита) уже записаны физические адреса начал страниц, так что, прибавив к началу таблицы страниц номер страницы (1023) - мы выходим на запись, в которой находится физический адрес начала нужной нам страницы. Остаётся только прибавить к нему 1365 - смещение - и искомый физический адрес готов. В случае 64-битной организации памяти уровней трансляции в этой схеме не два, а четыре; в случае трансляции со страницами размером 4 Мбайт - последний уровень трансляции пропускается.
Зачем вообще понадобилась столь сложная схема и почему было нельзя ограничиться одной таблицей трансляции? Всё дело в размере таблиц. Для 32-битной адресации памяти и страниц размером 4 Мбайт необходимый размер таблицы составляет всего лишь 4 или 8 Кбайт памяти, но для более востребованных 4 Кбайт - страниц, и, еще хуже, для 64-битной адресации памяти, необходимые размеры таблицы получаются гораздо большими - от 4-8 Мбайт до 8 Гбайт и даже 8 Тбайт. Во времена 386-х процессоров даже 4 Мбайт для таблицы трансляции адресов одной программы казалось слишком большой цифрой (а, учитывая, что на компьютере могут быть одновременно запущены сотни программ, и для каждой потребуется минимум по 4 Мбайт физической памяти - это и для современных систем слишком много); и потому выбор был сделан в пользу двухуровневой трансляции, при которой трансляцию можно остановить еще на «верхнем» уровне, указав для некоторых записей в «таблице директорий», что они не соответствуют никаким реальным физическим адресам и убрав, таким образом, необходимость в указании для целого диапазона адресов записей в таблице трансляции.
Кстати, сегментация (в 32-битных процессорах) даже с виртуальной памятью всё равно сохраняется. То есть реальные адреса, упоминающиеся в программе, вначале превращаются с учётом сегментов в «линейные», а уже они с помощью таблицы трансляции - в реальные «физические» адреса.
Трудно поверить, но, казалось бы ничем глубоко принципиальным не отличающаяся от обычной сегментированной модели памяти, память виртуальная даёт системному программисту практически всё, чего только его душа пожелает. Дело в том, что собственно усовершенствованной «трансляцией» адресов (которая сама по себе снимает все проблемы сегментированной оперативной памяти) виртуальная память не ограничивается. Вся «соль» технологии - в том, что для каждой записи в таблице трансляции адресов (фактически - для каждого диапазона адресов виртуальной памяти) определен набор специальных флагов, которые реализуют:
- Защиту важных участков оперативной памяти от перезаписи.
Один из простейших «флажков», который указывается для адресов виртуальной памяти - это флажок «только для чтения», позволяющий защитить определенные области виртуальной оперативной памяти от записи. К примеру, обычно read-only объявляются страницы, содержащие машинный код программы.
- Защиту программ от вирусов.
Основа новомодных «антивирусных» технологий вроде Microsoft Data Execution Prevention, обеспечивающих надёжную защиту компьютера от эксплойтов, использующих атаки типа «переполнение буфера», - крошечный битик в таблице трансляции (No eXecute - NX у AMD, и eXecute Disable, XD - у Intel), запрещающий выполнение машинного кода из определенных участков памяти.
- Защиту операционной системы.
Специальный бит позволяет определить некоторые участки оперативной памяти как «системные» и принципиально недоступные обычному приложению как для чтения, так и для записи.
- Эффективный менеджмент оперативной памяти.
Целый ряд специальных битов позволяет операционной системе отслеживать, по каким адресам программа читала или записывала данные, и определить «глобальные» страницы памяти, общие для всех программ в процессоре.
Но самый главный бит в таблице трансляции - это «нулевой» бит P - Present, обеспечивающий собственно
- По-настоящему виртуальную память.
На самом деле, назначение этого бита довольно простое - если он «сброшен» (установлен в 0), то любое обращение к оперативной памяти по этому адресу вызывает системную ошибку (исключение), называющуюся Page Fault (#PF). Но сколько же на основе этой «простоты» удаётся построить! Ведь, по сути дела, P-флаг, - это указание процессору, что для обработки обращения программы к данному адресу памяти требуется обратиться за помощью к операционной системе.
Судите сами: простейшее применение P-флага - это реализация своп-файла, позволяющего использовать жёсткий диск вместо физической оперативной памяти.
Идея в том, что мы можем для некоторых страниц виртуальной памяти не ставить им в соответствие никакого физического адреса оперативной памяти, а «сбросить» для соответствующих записей в таблице трансляции P-флаг и сохранить страницу в файл на жёстком диске. Если обращений к данной странице не происходит - то всё хорошо. Если происходит - то генерируется исключение #PF. По сути своей процессор просто приостанавливает выполнение текущей программы, и заглядывает в свой «справочник по действиям в нештатных ситуациях» - специальный участок памяти, в котором прописано, какую подпрограмму операционной системы вызывать в том или ином случае. В полном соответствии со стандартом, процессор вызывает обработчик исключения #PF - один из ключевых фрагментов любой операционной системы. Обработчик (фактически - операционная система) - «смотрит» на возникшую ситуацию («программа такая-то полезла в память по адресу такому-то и была остановлена потому что флаг Present был сброшен»), определяет, что данному адресу соответствует страница памяти, которой нет в оперативной памяти, но которая есть на жёстком диске - и начинает действовать:
- Он выбирает из физической памяти еще никем не занятую страницу, или даже освобождает одну из страниц, сохраняя её данные на диск, и сбрасывая соответствующий P-флаг в таблице трансляции.
- Читает нужное место своп-файла, копируя данные из неё в эту страницу.
- «Модернизирует» таблицу трансляции, прописывая в ней новый физический адрес для страницы, из-за которой случился сбой.
- Обновляет при необходимости данные в буфере TLB.
После этих манипуляций «проблемный» адрес виртуальной памяти, ссылающийся на несуществующую в физической памяти страницу становится уже не таким уж и «проблемным» - нужные данные уже загружены в память, и таблица трансляции нужным образом обновлена. Так что обработчику сигнала #PF остаётся только возвратить управление изначально работавшей программе - и последняя продолжит свою работу, как ни в чём не бывало, даже не догадываясь о том, что в каком-то её месте одно-единственное обращение в память спровоцировало столь длинную и сложную процедуру «свопа» данных в физической памяти и на жёстком диске.
Другие «популярные» применения P- флага виртуальной памяти позволяют реализовывать, к примеру технику «мэппинга файлов на память». «Мэппинг» - это когда программа по технологии, аналогичной технике свопинга, отображает по запросу приложения тот или иной файл в пространство виртуальных адресов программы. То есть можно добиться того, чтобы попытка чтения ячейки памяти #13323658 выливалась бы в автоматическое чтение какого-нибудь файла program.data с позиции 3446. Это, во-первых, весьма удобно (файл не нужно «читать» или «писать» - он уже доступен программе в виде обычного массива или набора массивов), во-вторых, очень быстро (производится лишь минимально необходимый набор действий по загрузке или записи данных), а в-третьих, очень эффективно (файл автоматически «кэшируется» в оперативной памяти, неиспользуемые страницы из этого кэша автоматически же убираются, освобождая физическую память, при сохранении сохраняются только действительно изменившиеся фрагменты файла, а не всё подряд, и т.п.). Хотя из-за ограничений сравнительно узкого доступного программе, работающей под управлением 32-битных версий Microsoft Windows, виртуального пространства в 2-3 Гбайт, и весьма громоздкой и неудобной реализации данной техники средствами Win32 API, используется она достаточно редко.
Более сложный пример, задействующий виртуальную память: реализация систем с якобы общей памятью в системах, где эта память изначально раздельна. Например, в разных компьютерах, соединенных при помощи локальной сети (в общем случае - в кластерах). Идея подобных систем состоит в том, чтобы при обращении программы по виртуальному адресу, соответствующему «чужой» памяти, вызывать обработчик, который сгенерирует обращение по сети к «чужой» машине, получив которое, эта машина выполнит нужную операцию с памятью и вернёт первоначальной машине ответ, который отобразится в программе. В результате можно добиться такого эффекта, что у нескольких физически совершенно разных компьютеров для программ виртуальная память будет пересекаться, или вообще полностью совпадать.
Это и есть суть «виртуальной памяти» - пользовательская программа никогда не может с уверенностью утверждать, что скрывается за абстрактным виртуальным адресом. Мы можем как угодно «дурачить» её, осуществляя за её спиной подтасовки с реальными адресами, и добиваться с этой помощью самых разнообразных эффектов. Впрочем, об этом мы поговорим в следующем разделе. А пока - перечислим основные и более востребованные преимущества виртуальной памяти:
- Виртуальная память обладает всеми преимуществами сегментированной.
- Но при этом размеры виртуальной памяти, выделенной программе, могут сколь угодно гибко изменяться.
- Виртуальная память может «физически» размещаться не только в оперативной памяти, но и на жёстком диске и даже в Сети.
- Виртуальная память не обязана быть непрерывной - её можно «нарезать» вообще как угодно, лишь бы это нам было удобно.
- Можно задавать произвольное число «пересекающихся» областей виртуальной памяти для разных программ, вплоть до того, что одни и те же данные будут многократно отображены в адресное пространство программы по разным адресам.
- Виртуальная память обеспечивает очень гибкую многоуровневую защиту оперативной памяти, позволяющую отлавливать любые ошибочные действия программы.
- И не только ошибочные: в задачах отладки приложений виртуальная память позволяет, к примеру, отследить в любой момент такое «отладочное событие», как простое чтение программой того или иного адреса в памяти.
Минусов у виртуальной памяти всего два. Во-первых, она существенно замедляет работу компьютера (даже простая трансляция виртуальных адресов, не попавших в TLB - очень неторопливое занятие; обработка же события #PF - и вовсе способна занять сотни тысяч тактов процессора); а во-вторых, - сложна и абсолютно непрозрачна для рядового программиста.
